Introduction
J'ai récemment pris part à une discussion sur la possibilité d'identifier des bots jouant sur les sites de poker en ligne, simplement en étudiant les statistiques de jeu proposées par tous les trackers tels que Holdem Manager ou Poker Tracker. Etant moi-même en train de quitter le milieu du poker, j'ai décidé de regrouper dans un article mon expérience sur la question, en espérant que cela puisse éventuellement sensibiliser les joueurs sur ce sujet, et donner des pistes pour démarrer à ceux que ça peut intéresser.
Le concept de base
La première idée d'un botter est d'automatiser complètement le processus de jouer au poker en ligne. Avoir un bot permet potentiellement de le laisser jouer seul, pendant que l'on fait soi-même tout autre chose. L'idée est tentante. Et une fois que l'automatisation est fonctionnelle, une deuxième idée fait souvent son apparition : la montée en échelle. Puisqu'un bot est totalement fonctionnel seul, pourquoi ne pas en lancer un deuxième qui ferait lui aussi sa vie de son côté? Et pourquoi s'arrêter à deux, quand on peut en lancer 5, 10 ou 50 et mutiplier ses gains potentiels par le même facteur? Bien sûr, les sites ont mis en place des garde-fous pour éviter ce genre de phénomène, mais ceux-ci sont contournables. Ainsi, les botters embauchent souvent leurs amis, leurs conjoints, les collègues, frères et soeurs, cousins etc. en leur proposant une petite part du gâteau en échange de la possibilité de jouer officiellement sous leur identité. Les comptes sont donc ouverts aux noms de ces connaissances, et les botters prévoyants se débrouillent pour que tous ces comptes jouent avec des adresses IP clairement différentes.
Une faille majeure dans ce plan est que tous ces bots reposent sur un moteur de jeu unique, et vont donc jouer exactement de la même façon sur une situation donnée, systématiquement. Un joueur lambda aura beaucoup de mal à s'en rendre compte, même en jouant souvent contre ces bots, car les statistiques de jeu s'affichant sur son tracker mettraient potentiellement un temps infini à converger exactement sur les mêmes valeurs (sachant que dans la pratique une situation de jeu ne se reproduit jamais exactement : les mêmes joueurs aux mêmes positions avec les mêmes cartes distribuées, le même historique etc.). Toutefois, si l'on dispose d'un échantillon de mains jouées suffisamment large, il est possible d'arriver à voir des similitudes de jeu entre deux comptes suffisamment fortes, au point que pour l'opérateur le doute soit trop important pour continuer à laisser les comptes suspects jouer sur son site.
Cet article va illustrer la procédure qu'un joueur peut utiliser pour rechercher ces similitudes. Il va se baser sur deux études réelles auxquelles j'ai pris part personnellement, en 2014 et 2015.
La récupération des données
Pour étudier des statistiques, il faut des données. Le problème dans le cas présent, c'est qu'il en faut beaucoup, et qu'elles sont difficiles à obtenir. Idéalement, on veut un sample de mains massif tout en étant relativement contraint dans le temps (les joueurs évoluent, les bots aussi, faire des statistiques sur des mains jouées à plusieurs années d'intervalle présente donc peu d'intérêt). Les quelques joueurs qui effectuent un volume de jeu massif (par exemple les Supernova Elites sur PokerStars.fr ou les Red Diamonds sur Winamax) disposent probablement, via leur tracker, d'une base de données suffisamment importante pour trouver des résultats intéressants. Mais pour l'ensemble des autres joueurs de la communauté, c'est bien plus compliqué. Il existe deux solutions, mais l'une comme l'autre sont théoriquement prohibées par les termes d'utilisation des sites de poker en ligne.
La première possibilité pour obtenir une base de données massive consiste en l'achat sur internet de mains jouées par d'autres. Il existe plusieurs sites commerciaux qui proposent contre rémunération un fichier zip contenant des dizaines/centaines de milliers de mains jouées sur un site, une période et des limites spécifiés par l'acheteur. Les mains peuvent ensuite être importées sur n'importe quel tracker pour être analysées, de la même manière que des mains que l'on aurait jouées soi-même. Dans la première étude, concernant des joueurs de PokerStars.fr, c'est de cette manière qu'a été constituée la base de données qui m'a été fournie.
La deuxième possibilité consiste en un regroupement des bases de données de plusieurs joueurs réels. C'est la solution qui a été utilisée pour la deuxième étude, celle concernant des joueurs du réseau IPoker.fr.
On peut comprendre pourquoi ces deux pratiques sont prohibées par les opérateurs : l'utilisation de mains jouées par d'autres que soi peut procurer au joueur un avantage injuste, il aura pu acquérir des connaissances sur certains joueurs sans avoir eu à les jouer sur une table. L'utilisation de ces données dans une optique purement de détection de bots me paraît relever d'un problème éthique bien différent, mais philosopher sur les termes d'utilisation des sites de poker n'est pas l'objet de cet article, à chacun donc de prendre (ou pas) les risques qu'il juge nécessaire pour effectuer ses recherches.
Etude #1 : PokerStars.fr, juillet 2014
Cette base de données est assez importante en taille pour que l'on se permette de n'étudier que les joueurs sur lesquels on possède un échantillon supérieur à 100k mains jouées sur une table "pleine" (5 ou 6 joueurs). On est obligés de filtrer le nombre de joueurs présents à table pour éviter de se retrouver avec des mains HU ou très short-handed qui rendraient les statistiques inutilisables. Le fait de ne garder que les échantillons supérieurs à 100k mains nous permet d'être relativement satisfaits sur la convergence des statistiques obtenues. Il nous reste alors 42 joueurs sur lesquels on va étudier 25 statistiques. Il convient de noter que la plupart des ces statistiques sont au moins légèrement corrélées, ce qui pollue un peu les calculs de similitudes que l'on effectuera par la suite, mais pas au point que ce soit un problème pour autant. Voici un échantillon de nos données :

Je me permets de poster ces quelques statistiques, car d'une part elles sont anciennes et non pertinentes à l'heure actuelle, et d'autre part ces premières colonnes ne contiennent aucune information qui pourrait porter préjudice aux joueurs mentionnés.
Il s'agit ensuite de standardiser le contenu des 25 colonnes de statistiques. Une définition plus complète est disponible ici pour ceux qui ne seraient pas familier de l'utilisation statistique de ce terme. L'idée est de ramener l'ensemble des colonnes sur une échelle unique qui nous permet de les comparer plus justement. Pour illustrer simplement cette idée en termes de poker, 50% et 55% de cbet au Flop, c'est "un peu pareil", alors que 5% et 10% de 3bet Préflop, c'est vraiment très différent, pourtant il n'y a à chaque fois que 5% d'écart entre les 2 valeurs. La standardisation statistique permet d'harmoniser l'ensemble des 25 colonnes sur une distribution unique.
Une fois les valeurs harmonisées, il ne reste plus qu'à déterminer le degré de similitude entre chaque joueur. Pour cela, il existe plusieurs métriques possibles, j'ai choisi la distance euclidienne pour faire simple et efficace (plus de détails ici pour les curieux). L'idée est d'imaginer chaque joueur comme un point dans un espace, dont la position est déterminée par l'ensemble des statistiques le concernant. Plus 2 point sont rapprochés, plus ces joueurs ont des statistiques proches et donc un style de jeu similaire.
A titre de repère pour la suite, on obtient une distance moyenne de 6.76. Voici la matrice de distances :

Les joueurs dont la ligne/colonne est plutôt claire ont un jeu relativement atypique par rapport aux autres joueurs à fort volume. A l'inverse, ceux dont la ligne/colonne est majoritairement sombre ont un jeu très classique, popularisé depuis des années par les forums spécialisés et les sites de vidéo training. Si on cherche les couples de joueurs dont la distance est inférieure à 3, on obtient ceci :

Un unique résultat : le couple justEdge1/Lando4man. Cela tombe bien, ce sont les 2 pseudos qui étaient suspectés par plusieurs joueurs réguliers depuis des mois. La suspicion était principalement dûe aux sizings assez uniques utilisés par ces joueurs, ainsi que par le fait qu'ils semblaient être aux tables en permanence mais ne jouaient jamais de coups l'un contre l'autre. Les statistiques confirment qu'ils ont un jeu très similaire, plus similaire que n'importe quel autre couple de joueurs parmi ceux sur lesquels on a un sample de mains supérieur à 100k. En soi, ce n'est pas un crime, ce qui est intéressant c'est de voir jusqu'à quel point cette similarité est supérieure à la plus forte similarité observée entre deux joueurs réels. Pour cela, on va zoomer sur les distances de ce joueur ainsi que sur celles d'un autre joueur, à priori non suspect lui.
Ce qui est intéressant, c'est que cette distance de 3.010 entre xxTof59xx et tib0rk0vaX est la deuxième plus faible distance sur l'ensemble de la base de données. Il y a donc un point complet entre la distance entre les deux comptes suspicieux et la plus petite distance entre deux joueurs humains. C'est énorme, il suffit de regarder les écarts entre les autres distances pour le comprendre.
Une version simplifiée de cette étude a été portée à l'attention du site, qui a mené sa propre investigation. Ils disposent de données autrement plus complètes : totalité des mains jouées, possiblement les timings des clics et les mouvements de souris, etc. Au terme de cette étude, les joueurs justEdge1 et Lando4man ont été bannis, ainsi que le troisième, dino1550, même si sur notre échantillon la distance entre lui et les autres n'était pas suffisamment faible pour être concluante. Contrairement à l'usage en rigueur sur la version .com du site PokerStars, ici aucune compensation n'a été versée aux joueurs lésés, malgré le fait très probable que les fonds disponibles sur les comptes bannis ont été saisis par le site. Sans le travail des joueurs, on peut légitimement se demander combien de mois/années ces bots auraient pu continuer à siphonner de l'argent des tables de moyennes limites sur le site.
Etude #2 : IPoker.fr, juillet 2015
Le réseau IPoker avait à l'époque une fréquentation significativement plus faible que PokerStars, du coup les comptes suspects n'en étaient que plus visibles. Et des comptes suspects, ce n'est pas ce qui manquait sur IPoker, le même genre de joueurs étranges que les bots de PokerStars, des sizings assez uniques notamment. Le problème était qu'IPoker est un réseau regroupant plusieurs opérateurs partageant leurs tables, ayant chacun des intérêts particuliers qui n'allaient pas forcément dans le même sens. A ce titre, obtenir des avancées significatives était une mission ardue, et demander au réseau d'investir du temps et de l'argent sur la détection de bots fut une de ces missions ardues. Un autre problème était l'absence de possibilité d'acquérir des bases de données significatives.
De guerre lasse, un groupe regroupant certains joueurs réguliers de moyennes limites a fini par accepter de fournir leur base de données personnelle récente à un tiers de confiance, afin que celui-ci consolide l'ensemble pour que l'on puisse avoir une base de travail un minimum décente. Malgré ces efforts, cette base est très nettement plus petite que la précédente. Pour cette étude, j'ai dû rabaisser le seuil minimal à 20k mains jouées, en sachant que cela ternit forcément la qualité des résultats obtenus (on est loin d'avoir un échantillon suffisant pour que l'ensemble des statistiques ait le temps de converger correctement). Même en rabaissant le seuil aussi bas, il ne reste que 37 joueurs pour cette étude.
De la même manière que précédemment, on a standardisé les données, puis calculé la distance euclidienne entre chaque joueur. On obtient une distance moyenne de 6.82, en ligne avec ce qu'on a obtenu lors de la première étude. Voici la matrice :
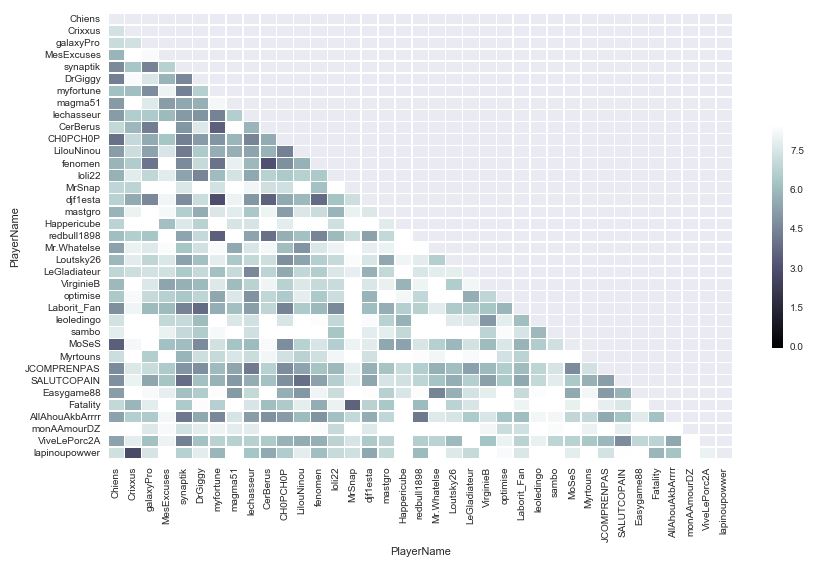
Comme précédemment, on va descendre le seuil à une distance inférieure à 3, pour avoir une première idée :

La distance la plus courte observée sur la base de données est de 2.8 exactement, entre Crixxus et lapinoupowwer. Cette distance est significativement plus importante que la distance observée entre les 2 bots sur PokerStars.fr. Un petit détail toutefois : ces deux pseudos appartiennent en fait au même joueur! Il est en effet aisé (et parfaitement autorisé) de changer régulièrement de pseudo sur IPoker.fr, et cette base de données comprend visiblement des mains de ce joueur jouées avec son ancien et son nouveau pseudo. Le fait que la distance soit quand même relativement importante montre bien le problème de travailler sur un échantillon de mains trop faible. Avec 100k mains sur chaque compte, il est très probable que l'on serait arrivé à une distance similaire à celle observée précédemment sur les deux bots.
On remarque aussi 2 autres couples très proches. En augmentant progressivement le seuil on arrive à cette matrice qui met en avant quelques nouveaux couples :

Les valeurs en elle-mêmes sont plutôt élevées et inexploitables à cause du faible échantillon. Il se trouve toutefois qu'à l'exception de la paire Chiens/MoSeS (deux joueurs réels non soupçonnés à priori), l'ensemble des comptes mis en évidence ici étaient déjà suspectés par le groupe de joueurs à l'initiative de l'études. Celui-ci a fini par mettre une certaine pression sur le réseau IPoker, par contacts privés réguliers tout d'abord puis en commençant à diffuser publiquement leur fortes suspicions sur ClubPoker.fr, le premier forum de France sur le poker, avec certains documents troublants, notamment des mains qui semblent illustrer un bot qui bug (par ici). Le réseau a fini par prendre acte, et a visiblement mené sa propre investigation, au terme de laquelle un nombre important de bots ont été bannis du réseau. Le nombre exact n'a pas été publié, mais le groupe de joueurs avait signalé au réseau une liste d'une quinzaine de comptes suspects (d'autres limites et formats de jeu ont été étudiés en dehors de la base de données présentée ici), tous ont disparu, d'autres aussi sûrement.
Il n'est évidemment pas possible de dessiner ces points sur un plan à 25 dimensions, toutefois il existe des techniques mathématiques de réduction de dimensions qui permettent de garder la majorité de l'information pour réussir à l'exprimer avec simplement deux ou trois dimensions et ainsi pouvoir la visualiser convenablement. Voici le résultat sur cette base :

Le groupe de points en rouge sur la gauche représente un groupe de bots qui a été banni. Même si l'échantillon était faible, la similarité entre les joueurs de ce groupe apparaît clairement. Le fait qu'aucun joueur réel n’ait de statistiques suffisamment similaires pour apparaître mêlé au groupe sur ce graphe conforte l'idée d'un groupe qui joue d'une manière unique par rapport au reste du pool de joueurs.
Les deux points en bleu clair, au-dessus du groupe de bots, sont les deux alias du même joueur "normal" discuté plus haut. Et un peu plus haut sur la droite apparaissent deux autres points qui avaient été "flaggés" sur la matrice de distance. Le compte Fatality a disparu en même temps que les autres bots, et sur le sujet du ClubPoker, quelqu'un avait posté des images (enlevées depuis) de 2 autres joueurs ayant des statistiques extrêmement similaires à Fatality. Il apparaît évident que ces 3 comptes étaient aussi des bots utilisant un moteur différent du premier groupe, même si sur l'échantillon utilisé sur cette étude les deux autres comptes n’apparaissent pas. Le compte flaggé avec Fatality sur la matrice de distances, MrSnap, n'a à ma connaissance pas été inquiété.
Ici encore, aucune compensation n'a été versée aux joueurs lésés, l'argent saisi sur les comptes bannis n'a pas été reversé, et ici encore on peut se demander combien de temps ces bots auraient continué à sévir sur le réseau sans le travail des joueurs. Un ami qui jouait énormément en NL50 et NL100 à l'époque m'a confié que les 7 comptes contre qui il avait joué le plus de mains sur la première moitié de l'année 2015 faisaient partie de la charrette de bots bannis. Ça laisse songeur sur l'état des parties en petites et micro limites, là où les joueurs ont probablement moins d'expérience pour repérer les comptes suspects. Il convient de mentionner, pour finir sur une note positive, que depuis cette dernière étude, d'autres bots ont été bannis en petites et moyennes limites sur Winamax et PokerStars.fr notamment, à priori sans que des joueurs en soit à l'origine, et des remboursements aux joueurs lésés ont cette fois-ci eu lieu dans les deux cas. Cela laisse penser que les sites commencent à se rendre compte de l'ampleur du phénomène et ont probablement décidé d'augmenter significativement leur implication sur ce sujet.
Article enrichissant, merci d'avoir détaillé la méthodologie ! Cependant, Serait-il possible de publier la formule utilisée pour standardiser les 25 colonnes de statistiques ?
RépondreSupprimerBonne nuit
Bonjour Alexandre,
Supprimermerci pour ton retour. L'étude ayant été réalisée en Python, j'ai utilisé le StandardScaler de l'excellent package scikit-learn (http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html).
La formule utilisée est celle généralement utilisée dans le processus de standardisation à savoir qu'on soustrait à chaque valeur la moyenne de l'échantillon, et on divise par l'écart type. Cela nous donne la distance en nombre d'écart-types par rapport à la moyenne de l'échantillon.
Hey, je tombe là-dessus à moitié par hasard, boulot intéressant :)
RépondreSupprimerAll the best,
ArtPlay