INTRODUCTION
Ces
derniers mois, j'ai choisi d'étoffer mes connaissances en Machine
Learning et en langage Python en m'essayant à plusieurs challenges,
principalement sur Kaggle. Je pense que c'est un excellent medium
pour apprendre, principalement par le biais des forums et des
kernels, où les meilleurs spécialistes mondiaux du domaine
partagent leur savoir de manière très altruiste. Ainsi,
généralement lorsqu'une compétition est terminée, plusieurs
compétiteurs ayant fini au sommet viennent partager leurs méthodes
sur le forum, et parfois même directement leur code source en
postant un lien vers leur repo GitHub correspondant.
Toutefois,
il est bien difficile aujourd'hui de finir parmi les meilleurs sur
une compétition Kaggle, bien plus qu'il n'y a ne serait-ce que 2 ou 3 ans (au regard des articles que l'on peut lire sur les solutions gagnantes de cette époque). Il faut désormais un espace de stockage énorme car
les datasets deviennent gigantesques, et une puissance de calcul
rarement disponible sur des PCs standards pour pouvoir faire tourner
des GridSearches pendant plusieurs jours, ou bien entraîner des
réseaux de neurones (via Keras pas exemple) sur des GPUs dernier
cri. Les meilleurs empilent bien souvent plusieurs dizaines de
modèles sur du stacking à 3 niveaux, parfois plus. C'est pour ça
que quand j'ai entendu parler du ChallengeData ENS (merci
Laurae),
ça m'a intéressé : des datasets qui ne nécessitent pas d'accès au cloud pour être étudiés, et des
compétiteurs qui ne sont pas forcément l'élite de l'élite
mondiale, mais (pour la plupart) “simplement” des étudiants des
meilleurs écoles de France (Polytechnique, ENS Cachan etc), ainsi que
certains passionnés dans mon genre.
Au
moment où j'écris cet article, je suis 1er sur 71 sur le Challenge
“Oze Energies”
et 2e sur 20 sur le Challenge “PlumeLabs”. Ce sont les
2 seuls challenges sur lesquels j'ai travaillé. Les compétitions se
terminent en Juin, et j'imagine sans peine que certains vont me
dépasser d'ici là, vu que je ne compte plus vraiment continuer à
travailler dessus. Accessoirement, peut-être certains tomberont-ils
sur cet article et y trouveront quelques idées (si c'est votre cas,
un petit merci dans les commentaires me ferait un grand plaisir).
J'aurais bien posté l'article sur le site du Challenge pour un souci
d'équité d'accès à l'information, mais il n'y a à l'heure actuelle aucun forum. Je vais me
concentrer ici sur le Challenge “Oze Energies”.


PREPROCESSING
La
première chose à faire quand on récupère un dataset, c'est une
exploration des données, pour avoir une idée du problème. Ici la
première particularité visible : il y a une dimension temporelle au
problème, et le training set s'étend de Janvier à Avril 2016
inclus, tandis que le test set consiste en le mois de Mai 2016. Il
s'agit donc de séries temporelles, avec les particularités qui
leurs sont propres, notamment en termes de validation des résultats
(on y reviendra).

On
voit aussi que les variables sont anonymisées. Toutefois l'énoncé
nous explique que x2 et x5 sont liées aux conditions météo
extérieures, tandis que x1, x3 et x4 sont des relevés de capteur
dans les bâtiments (j'ai par la suite renommé ces variables dans ce
sens, dans un souci de compréhension accrue : x2 devient WeatherA,
etc). Il y a également 5 variables cibles à prédire, sur
lesquelles on ne dispose d'aucune indication, si ce n'est que chacune
représente “des données sur un type de consommation d'énergie
utilisée pour contrôler le comportement thermique de chaque
bâtiment”.
Car
oui, il y a plusieurs bâtiments distincts, et c'est un facteur
essentiel. L'énoncé indique "Important
remark: for some buildings, some consumptions are not used to
heat/cool rooms. In this case, all data of the corresponding output
are set to 0 (zero) and this output has to be ignored (you do not
have to predict it). This is for instance the case for output y3 for
building with Id_bat 1."
Cette remarque montre que chaque bâtiment a un comportement unique.
Cette idée est encore renforcée quand on remarque le comportement
de certaines variables cibles en fonction du bâtiment sur le
training set :

Ici
on voit que sur le bâtiment 1 la variable cible y2 passe à une
consommation réduite mi-Février, puis devient nulle à partir
d'Avril (on peut penser à une variable liée au chauffage du
bâtiment). Sur le bâtiment 2, cette même variable cible montre une
très légère tendance à la baisse sur l'ensemble du training set,
mais rien de comparable à ce qui se passe sur le bâtiment 1.
Comment prévoir ces deux comportements si différents, concernant
pourtant une unique variable? Le choix que j'ai effectué a été de
séparer le problème initial en 4 problèmes différents (un par
bâtiment), en considérant que ce qui se passe dans un bâtiment ne
devrait pas influencer ce qui se passe dans un autre (corrélation
mais pas cause!). On ne peut pas prouver ce postulat, mais les
résultats obtenus ont plutôt confirmé cette idée.
Un
autre réflexe à avoir dans les premiers moments d'une analyse d'un
dataset est de regarder les données manquantes, et de réfléchir à
leur gestion. La plupart des implémentations d'algorithmes de
Machine Learning ne peuvent pas fonctionner sur un dataset contenant des
données manquantes. Il s'agit donc de remplacer ces données
manquantes par des valeurs réelles, et pour cela il existe
différentes stratégies. Pour des données numériques (comme ça va
être le cas ici), la stratégie la plus simple consiste à remplacer
ces données par zéro. Cela peut avoir du sens parfois : pour un
dataset immobilier, on peut imaginer une variable représentant la
surface du garage, et l'ensemble des propriétés ne contenant pas de
garage pourraient ne pas avoir cette variable renseignée, auquel cas
remplacer ces données manquantes par zéro ne serait pas un
non-sens. Concernant notre problème, les variables manquantes se
retrouvent ci-dessous :

Il
s'agit de relevés de capteurs ou de température. La stratégie qui
m'est apparue comme ayant le plus de sens a consisté en le
remplacement des données manquantes par la valeur médiane par
bâtiment par variable. Pour plus de précision, je limite la période
temporelle sur laquelle je récupère la médiane quand c'est
possible, en commençant par calculer sur la journée concernée,
sinon sur la semaine, sinon sur le mois (quand aucune mesure n'a été
effectuée sur la semaine concernée par exemple).
On
n'a d'ailleurs pas encore évoqué cette notion de temporalité. On
dispose à la base d'une variable Time
qui est une chaîne de caractère (par exemple “2016-01-01
00:00:00”).
Dans son format original, elle ne vaut pas grand chose, c'est juste
une variable catégorielle (par contraste avec une variable
numérique) qui a une valeur différente pour chaque observation. En
parsant cette chaîne de caractères, on peut immédiatement en
déduire pour chaque observation des nouvelles variables
potentiellement utiles (le mois, le jour du mois, l'heure), d'autres
qui le sont moins (l'année est toujours la même, les minutes et les
secondes qui valent tout le temps zéro). En poussant un peu plus
loin, on peut aussi en déduire d'autres variables temporelles : le
jour de l'année, la semaine, et le jour de la semaine. On ne crée
pas ces nouvelles variables par plaisir, elles contiennent de
l'information. Typiquement on peut imaginer que les consommations d'énergie devraient
être différentes le week-end par exemple, si on parle d'immeubles de bureaux standards.
Il
est évidemment possible d'aller bien plus loin dans le feature
engineering. J'ai essayé plusieurs pistes qui n'ont pas donné de
résultat probant. La seule autre idée qui ait fonctionné : ajouter
des variables représentant la médiane sur le training set de chaque
variable cible par bâtiment, puis par jour de la semaine, puis par
heure. En effet, on pouvait imaginer qu'il y aurait un pattern, que
connaître la valeur d'une variable cible chaque jeudi à 18h dans
l'ensemble du training set nous donnerait de l'information quand il
s'agirait de prévoir la valeur de cette même variable cible dans le
test set chaque jeudi à 18h. Pour avoir des idées intéressantes de
feature engineering, je vous renvoie vers l'excellent post de
Triskelion sur Kaggle :
Parlons
maintenant du set de validation privé. Dans la plupart des
compétitions de Machine Learning, afin d'éviter d'overfit le
leaderboard public, on fait de la cross-validation pour valider nos
résultats. Je ne vais pas réexpliquer le principe de la
cross-validation dans cet article. Sur la compétition "Oze Energies",
il y a cette notion de temporalité auquelle il faut faire très
attention. Si on se contente de faire de la cross-val brute sans
réfléchir, on se retrouve à faire des prédictions sur des folds
se situant dans le passé! Vu que le test set est temporellement
postérieur au training set, il n'y a pas 36 solutions pour se créer
un set de validation qui ait du sens : il faut que celui-ci soit
postérieur au set sur lequel on va faire de l'apprentissage. Le
training set originel comporte 4 mois de données, j'ai choisi la
simplicité avec un set de validation sur le 4e mois, et un
apprentissage sur les 3 premiers mois. Evidemment, au moment de
vouloir fournir des prédictions pour le leaderboard public, il ne
faut pas oublier de refaire un apprentissage sur l'ensemble du
training set originel cette fois-ci. Le set de validation que l'on a
crée pourra également être utilisé en fin de processus pour faire
de l'ensembling (on en reparlera).
Une
dernière remarque sur la manipulation du training set avant de
passer à l'apprentissage : comme mentionné précédemment, j'avais
déjà décidé de séparer le problème originel en 4 : un par
bâtiment. Cela signifie du coup splitter le training set en 4. Mais
pour chaque bâtiment, il y a 5 valeurs cibles à prévoir. C'est
donc sur 20 problèmes différents sur lesquels je vais travailler à
partir de maintenant. Encore une fois, je ne peux pas prouver que
c'est la meilleure manière d'aborder le problème, c'est juste celle
qui m'a parue avoir le plus de sens.
APPRENTISSAGE
Passons
maintenant à l'apprentissage. Nous sommes face à un problème de
régression, et il existe un grand nombre d'algorithmes de Machine
Leaning que l'on peut appliquer ici, étant donné qu'on a déjà
pris soin de faire en sorte de ne plus avoir de données manquantes.
L'approche la plus simple serait d'utiliser un modèle unique qui
montrerait de bonnes capacités prédictives. Une approche plus
élaborée serait d'utiliser un ensemble de modèles et de prendre la
moyenne des résultats de chaque modèle pour effectuer nos
prédictions. C'est ce qui se fait dans les Random Forests par
exemple, qui ne sont finalement qu'un simple ensemble d'arbres de
décisions.
Mon
expérience sur Kaggle m'a fait choisir de passer la majorité de mon
temps sur un algorithme nommé XGBoost. Historiquement, c'est un
algorithme utilisé dans la quasi-totalité des solutions gagnantes
sur les compétitions de ces deux dernières années (parfois en
combinaison avec d'autres modèles). XGBoost est l'abbréviation de
“Extreme Gradient Boosting” et repose sur le modèle des Boosted
Trees, un ensemble d'arbres de décisions dont l'apprentissage se
fait par Boosting, c'est-à-dire de manière séquentielle, chaque
nouvel arbre se basant sur les résultats déjà recueillis sur les
précédents. Pour une explication détaillée sur cet algorithme :
Sur
la compétition "Oze Energies", j'ai essayé d'autres algorithmes qui
m'ont donné des résultats sensiblement moins bons (régression
linéaire avec régularisation Ridge ou LASSO, Random Forests). Seul
l'algorithme LightGBM s'est approché des résultats de XGBoost, ce
qui n'est pas étonnant vu qu'ils se ressemblent fortemen (il est également basé sur un modèle de Boosted Trees).
Après
avoir fait tourner XGB sur le dataset (apprentissage puis
prédiction), on peut observer les résultats sur le set de
validation. Quand on regarde la mesure d'erreur utilisée dans cette
compétition (Mean Squared Error), on remarque des résultats très
variables selon la combinaison {variable cible; bâtiment}. On peut
visualiser ces erreurs pour essayer de mieux comprendre et
éventuellement améliorer notre process. Voici par exemple les
erreurs pour la variable cible "y1" dans le bâtiment 1 :

En
abscisse se trouvent les prédictions, en ordonnée les valeurs
réelles. Du coup la ligne rouge représente l'identité, des
prédictions parfaites. On voit qu'ici les prédictions sont
relativement groupées, proches de la ligne rouge, donc plutôt
correctes. Notre modèle a même correctement capté qu'il y avait 2
“paquets” distincts de valeurs. Les résultats sont parfois
beaucoup moins probants. Voici les résultats toujours pour "y1", mais
dans le bâtiment 3 cette fois-ci :
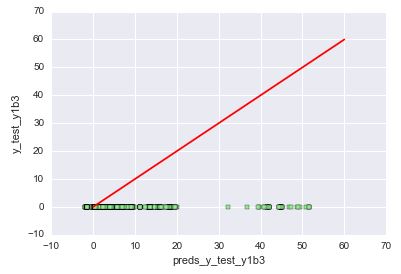
Le
modèle a prédit des valeurs comprises entre -2 et 100, tandis que
les valeurs réelles valent toutes 0. Comment expliquer cet échec?
Regardons la distribution de "y1" sur le bâtiment 3 sur l'ensemble du
training set :

On
voit que la variable passe brusquement à zéro au cours du 3e mois,
et reste à zéro ensuite. On rappelle que pour valider nos modèles,
on se content d'apprendre sur les 3 premiers mois et de valider sur
le 4e. Notre modèle a donc appris que la variable cible évoluait
entre 200 et 1000 sur 2.5 mois puis passait à zéro sur les 2
dernières semaines. Il a ainsi prédit des valeurs plus faibles que
celles observées sur les 2.5 mois du début, mais tout de même
au-dessus de zéro. On peut imaginer qu'avec un modèle qui donnerait
plus de poids aux observations les plus récentes, les prédictions
seraient sensiblement plus proches de zéro et les erreurs seraient
donc bien plus faibles. Un autre exemple de prédictions assez mauvaises avec "y3" dans le bâtiment 3
:


Encore
une fois, on voit que l'évolution de la variable cible est plutôt
chaotique : faibles valeurs pendant un peu plus de 2 mois, brusque
montée en puissance au cours du 3e mois, puis arrêt brusque, pour
repartir de manière encore plus volatile pendant le 4e mois. Il est
bien difficile, même pour un algorithme aussi performant que XGB, de
prédire un tel comportement dans le 4e mois. Enfin un dernier
exemple :


Ici
on remarque une distribution particulière de la valeur cible, par
paliers, avec une tendance globale à la baisse. Si cette baisse a
été plutôt bien captée par notre modèle, les paliers ne le sont
eux pas vraiment. On retrouve cette structure par paliers dans deux
autres combinaisons {variable; bâtiment}, c'est donc un point
d'amélioration potentielle important à creuser, je n'ai pas encore trouvé de solution satisfaisante.
On peut également
observer l'importance des variables d'apprentissage dans nos modèles.
On rappelle qu'on a construit un modèle différent par combinaison
{variable; bâtiment}, chacun effectuant son apprentissage sur un
dataset qui lui est propre, et donc l'importance de chaque variable
d'apprentissage peut évidemment varier d'un modèle à un autre. Il
paraît toutefois raisonnable d'espérer une structure relativement
similaire sur l'ensemble de ces modèles. A titre d'exemple, voici
l'importance des variables d'apprentissage pour le modèle concernant
la variable cible "y5" dans le bâtiment 4 (ici la valeur en abscisse
indique le nombre de fois où la variable est apparue dans un arbre)
:

Certaines des
variables d'apprentissage que l'on a rajoutées, comme DayOfYear, ont
eu une importance considérable. Ce n'est pas vraiment surprenant
pour une série temporelle, c'est la variable la plus granulaire qui
n'ait pas de valeur en doublon (alors que les valeurs de Hour se
répètent N fois, N étant le nombre de jours du dataset). L'impact
de certaines autres variables, comme Month, a été bien plus
négligeable. On pouvait aussi s'y attendre. En effet, d'une part le fait
qu'on travaille sur une série temporelle fait que le mois utilisé dans le test set n'a jamais été observé dans le training set, tout
au plus le modèle peut avoir parfois capté une tendance d'un mois
vers son suivant. De plus, l'information présente dans la variable
Month est, quelque part, également présente, mais de manière bien plus fine et
granulaire, dans les variables Week et DayOfYear. Les variables
médianes que l'on a rajoutées ont visiblement également joué un rôle
relativement important.
TUNING
On pourrait
s'arrêter là, après tout on a effectué un feature engineering
correct, on a utilisé un des algorithmes les plus puissants qui
soient pour l'apprentissage et les prédictions. Toutefois je ne me
suis pas étalé pour l'instant sur le paramétrage de XGBoost. Cet
algorithme, encore plus que la plupart des algorithmes de Machine
Learning populaires, expose un certain nombre de paramètres dont on
peut modifier la valeur. On peut modifier la profondeur maximale de
chaque arbre par exemple, ou bien encore le nombre d'observations
minimum que l'on réclame pour créer un nouvel enfant dans un arbre.
Il n'existe pas de
“valeurs miracles”, plutôt pour chaque dataset il existe une ou
plusieures combinaisons optimales de ces paramètres, propres à ce dataset. Bien
évidemment, certains ont automatisé ce processus d'optimisation.
Les deux méthodes les plus connues sont le RandomizedSearch et le
GridSearch. Le GridSearch va tester l'ensemble des combinaisons parmi
les valeurs possibles qu'on lui fournit pour chaque paramètre. Son
principal avantage est son exhaustivité, son principal défaut est
le fait que cela peut prendre beaucoup, beaucoup de temps. Une
version simplifiée a donc vu le jour, le RandomizedSearch, qui va
tester X combinaisons choisies au hasard, X étant paramétrable. On
n'a plus l'exhaustivité ici, mais on peut souvent trouver des
combinaisons très performantes en choisissant nous-même le temps
qu'on est prêt à attendre.
J'ai choisi une
troisième voix, l'optimisation Bayesienne. C'est une méthode qui
cherche à trouver la valeur maximale d'une fonction inconnue, en
aussi peu d'itérations que possible. Je ne rentrerai pas dans les
explications mathématiques du concept, j'en serais d'ailleurs bien
incapable, mais il vous reste toujours Google! Niveau implémentation,
par contraste avec un GridSearch, ici on ne fournit pas un ensemble
de valeurs possibles pour chaque paramètre, mais un borne minimale
et une maximale, l'algorithme se chargeant d'explorer cet espace de
manière intelligente. Pour un exemple d'implémentation en Python : https://github.com/fmfn/BayesianOptimization

Voici un exemple
des résultats obtenus pour les paramètres min_child_weight et
colsample_bylevel. Les couleurs représentent la MSE de chaque
combinaison testée, en extrapolant avec la bibliothèque "scipy" pour obtenir un joli
dessin. On peut observer qu'un tuning correct des paramètres est
capital, avec une MSE qui peut varier du simple au triple! Sur cet
exemple, on pourrait se dire que les résultats sont quand même
globalement mauvais avec des valeurs élevées pour min_child_weight,
ce qui intuitivement a du sens : si les critères pour créer un
nouvel enfant dans l'arbre sont trop compliqués à atteindre, on se
retrouvera avec des arbres trop simplistes, qui ne captent pas
certaines subtilités de l'information contenue dans le dataset. On
peut également se dire que des valeurs faibles pour
colsample_bylevel donnent des mauvais résultats, ce qui a aussi du
sens : en se privant de trop de variables d'apprentissage à chaque
niveau des arbres, on risque de passer à côté d'une partie de
l'information trop souvent. On peut créer ce graphe pour chaque
paire de paramètre et faire de la cross-examination. Ainsi, l'image
ci-dessous tend à confirmer qu'il ne faut pas de valeur trop haute
pour min_child_weight, surtout combinées avec des valeurs faibles
pour max_depth.

Une fois que l'on
a une meilleure idée des plages de valeurs qui ne paraissent pas
idéales pour chaque paramètre, on peut relancer l'algorithme sur
des nouvelles plages améliorées, et itérer de cette manière
plusieurs fois jusqu'à avoir une bonne idée des plages de valeurs
qui donnent les meilleurs résultats.
ENSEMBLING
On peut s'arrêter
là, avec des prédictions bien calibrées provenant d'un algorithme
puissant entraîné sur un dataset convenablement enrichi. C'est
d'ailleurs ce que j'ai commencé par faire ici : le score obtenu par
mon XGB était de 13044, suffisant pour prendre la première place du
challenge (le 2e score au moment de l'écriture de cet article est de
13390). Toutefois, un bon ensemble est juste trop puissant face à un
modèle unique, aussi bien calibré soit-il. J'ai eu envie d'essayer
un ensemble simple, avec seulement un second modèle.
Il existe deux
grandes familles d'ensembles. Dans la première (le “stacking”),
on utilise les prédictions sur le set de validation comme des
variables d'apprentissage pour un modèle de second niveau. Plus on a
de modèles de 1er niveau, si possible assez différents les uns des
autres, plus on se donne de chances de capter de l'information dans un ou plusieurs modèles au niveau supérieur. Comme mentionné
précédemment, les meilleurs Kagglers additionnent parfois plus de
cent modèles au premier niveau (des combinaisons entre différents
algorithmes et différents datasets). La deuxième famille consiste à
faire simplement une moyenne pondérée des prédictions des
différents modèles qu'on a sous la main, toute la finesse étant
dans la manière de pondérer. C'est la solution que j'ai choisie, en
basant mon implémentation sur cette discussion :
J'ai donc ensemblé
mes 2 modèles XGB et LightGBM, en sachant que ce sont 2 modèles
avec une structure très similaire, or l'ensembling fonctionnera
d'autant mieux que les modèles utilisés sont différents. Je
m'attendais à une légère amélioration de mon score, et j'ai donc
été assez surpris de voir que l'ensemble scorait 650 points de
mieux que mon XGB seul, une démonstration de plus de la puissance
des ensembles en Machine Learning. Je montre ci-dessous les poids
optimaux trouvés pour chaque variable cible. On constate que la
somme n'est jamais tout à fait égale à un, ce qui n'est pas bien
important, cela signifie juste que mes 2 modèles avaient tendance à
sous-évaluer ou sur-évaluer leurs prédictions de manière générale
selon la variable cible.

CONCLUSION
Pour obtenir un
score raisonnable dans une compétition de Machine Learning, il
suffit généralement de se concentrer sur les points suivants :
- Un feature engineering basé sur l'observation des données et le bon sens
- L'utilisation d'algorithmes performants
- Le tuning de ces algorithmes en utilisant des méthodes automatisées
- De l'ensembling de plusieurs modèles afin de combiner leur capacité à capter de l'information.
*****
Bonjour le code est-il disponible ?
RépondreSupprimerMerci
RépondreSupprimerMerci
RépondreSupprimer